Since launching our website and initiating our first call for syllabi on March 24th, the CUNY Syllabus Project has received upwards of 70 syllabi from all over the CUNY system. The next phase of the project calls for an analysis of select data and metadata to identify pedagogical trends across disciplines and across the CUNY campuses. We’ve chosen 65 syllabi to analyze as an initial dataset. Although our sample size is smaller than what we were aiming for this round, these 65 syllabi provide a first glimpse of the pedagogical practices going on at CUNY.
ROUND ONE
The Raw Numbers:

The Data
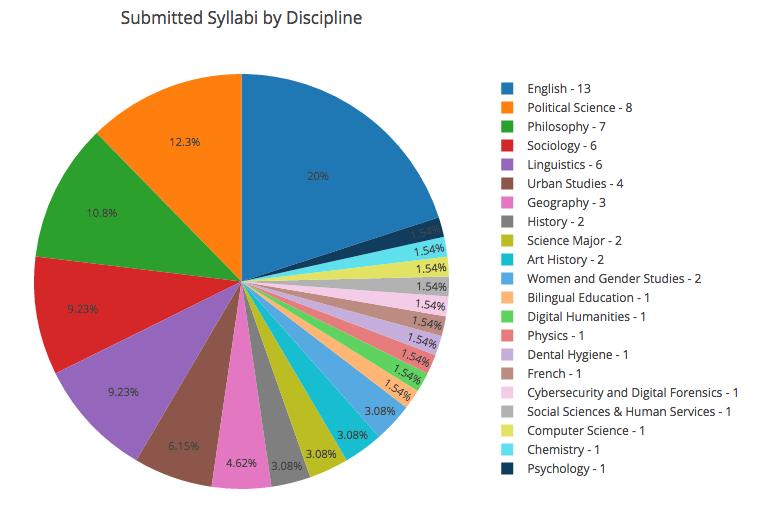
Submitted Syllabi by Discipline
We’ve received syllabi from a wide range of disciplines, from Art History and Computer Science to Physics and Urban Studies. English was the most represented discipline (13 submitted syllabi), with Political Science (8 submitted syllabi), Philosophy (7 submitted syllabi), Sociology (6 submitted syllabi), and Linguistics (6 submitted syllabi) following behind.
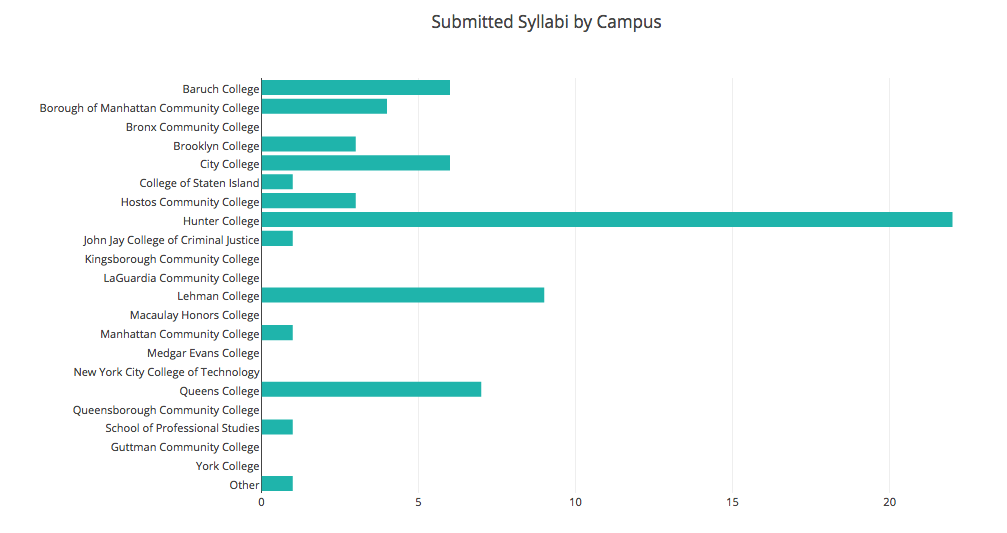
SUBMITTED SYLLABI by campus
We’ve received syllabi from more than half of the CUNY campuses. Hunter College provided substantially more syllabi than any other campus – 22 syllabi in total – while the next most represented campus, Lehman College, provided 9 syllabi.
SUBMITTED SYLLABI BY YEAR
2015 was the most represented year with 17 submitted syllabi. We anticipate that 2015 and 2016 will remain the most represented years for future submissions.

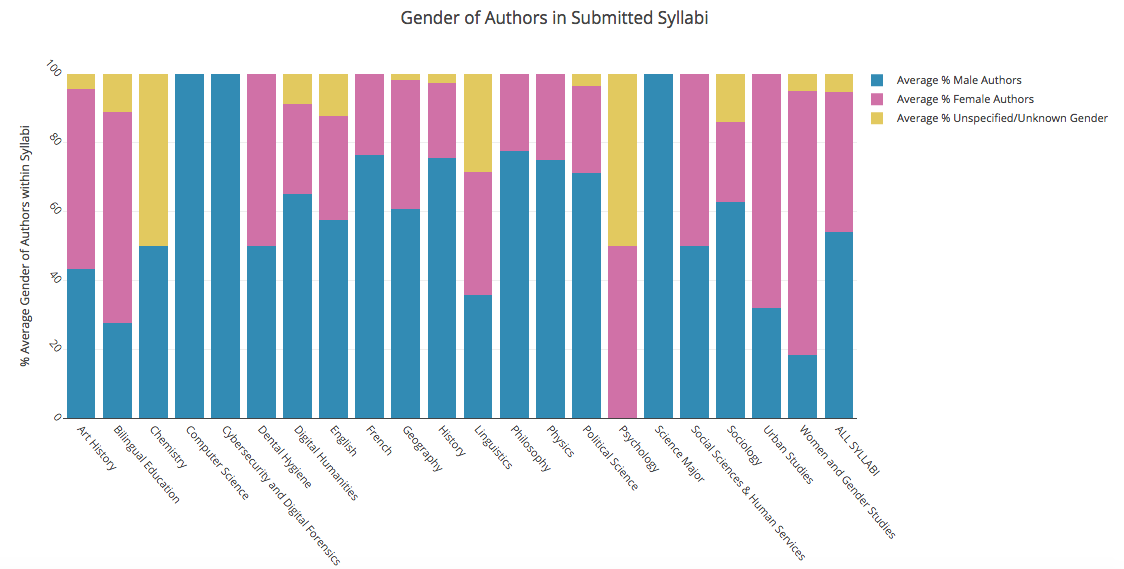
author gender
The majority of our initial data visualizations involve the metadata that we’ve collected. In addition to the metadata collection this round, we hand combed through each syllabus to identify every author within each syllabus. We were able to determine the gender identity of most of the authors within each syllabus and can show an initial comparison between disciplines. The majority of syllabi for each discipline contain more male authors with Bilingual Education, Psychology, Women and Gender Studies, and Urban Studies as exceptions.
We hope to share more data visualizations soon – please contribute a syllabus to help us create a more robust dataset for the next round!
Hi Annie, you’re absolutely correct. We’d love to be more evenly representative of the CUNY system. It’s a bit difficult to do when submissions are voluntary, but we are trying to spread the word as much as possible. Posting the call for submissions to the Kingsborough faculty email system would be fantastic – thank you!
I’m a prof at Kingsborough, and I think your project is super-interesting! However, I notice that your data is not evenly representative of the CUNY system. Today is the first I’ve heard of your project. Would you like me to post your call for submissions and link to submit on Kingsborough’s faculty email system?